

For all the advances in AI-generated video, one thing has often been missing: sound that feels real. Tencent’s Hunyuan lab believes it has found the answer with Hunyuan Video-Foley, a new model designed to generate lifelike audio that syncs seamlessly with on-screen action.
Why Sound Matters in AI Video
Visuals alone rarely tell the full story. In filmmaking, the rustle of clothing, the crack of thunder, or the clink of a glass are brought to life by Foley artists, experts who recreate everyday sounds with precision. But until now, AI systems have struggled to replicate this craft.
The problem, researchers say, is “modality imbalance.” Many video-to-audio models focused too heavily on text prompts while ignoring the details of the video itself. For example, a clip of a busy beach described only as “waves” might generate ocean sounds—but miss the footsteps in the sand or the cry of seagulls. The result felt flat and artificial.
Tencent’s Three-Part Solution
Tencent’s team tackled the challenge on several fronts:
- Building a better training set: They compiled a 100,000-hour dataset of video, audio, and text, carefully filtering out poor-quality clips with muffled or missing sound.
- Smarter AI architecture: The system first locks onto the exact timing of visual cues—like matching a footstep to the moment it hits the pavement—before layering in context from text prompts. This ensures both accuracy and atmosphere.
- High-quality sound alignment: Using a strategy called Representation Alignment (REPA), the model constantly compares its output against professional-grade audio features, guiding it toward cleaner, richer, and more stable results.
Today we're announcing the open-source release of HunyuanVideo-Foley, our new end-to-end Text-Video-to-Audio (TV2A) framework for generating high-fidelity audio.🚀
— Hunyuan (@TencentHunyuan) August 28, 2025
This tool empowers creators in video production, filmmaking, and game development to generate professional-grade… pic.twitter.com/mff2m5xFvC
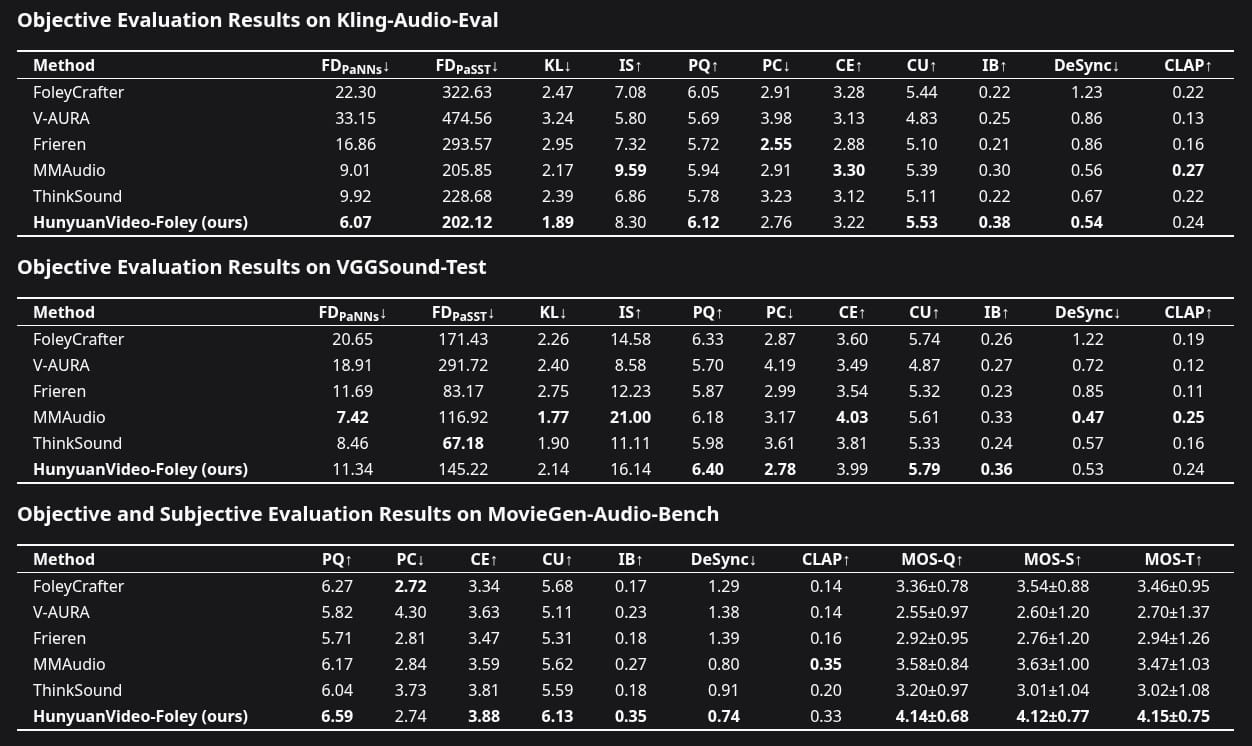
Tested Against the Best
When evaluated against other leading models, Hunyuan Video-Foley consistently outperformed competitors. Human listeners rated its audio as more natural, better timed, and more in tune with the visuals. Technical benchmarks confirmed the improvements.
What This Means for Creators
The breakthrough could have far-reaching implications for content creators. From independent animators to professional filmmakers, anyone working with AI-generated video may soon have access to audio that doesn’t just fill silence but deepens immersion.
By bringing the artistry of Foley into the realm of automation, Tencent’s model helps close the gap between today’s experimental AI clips and tomorrow’s fully immersive media.



