

Anthropic has opened up about how it keeps its AI assistant, Claude, both useful and safe—an increasingly critical challenge as AI tools grow in capability and reach.
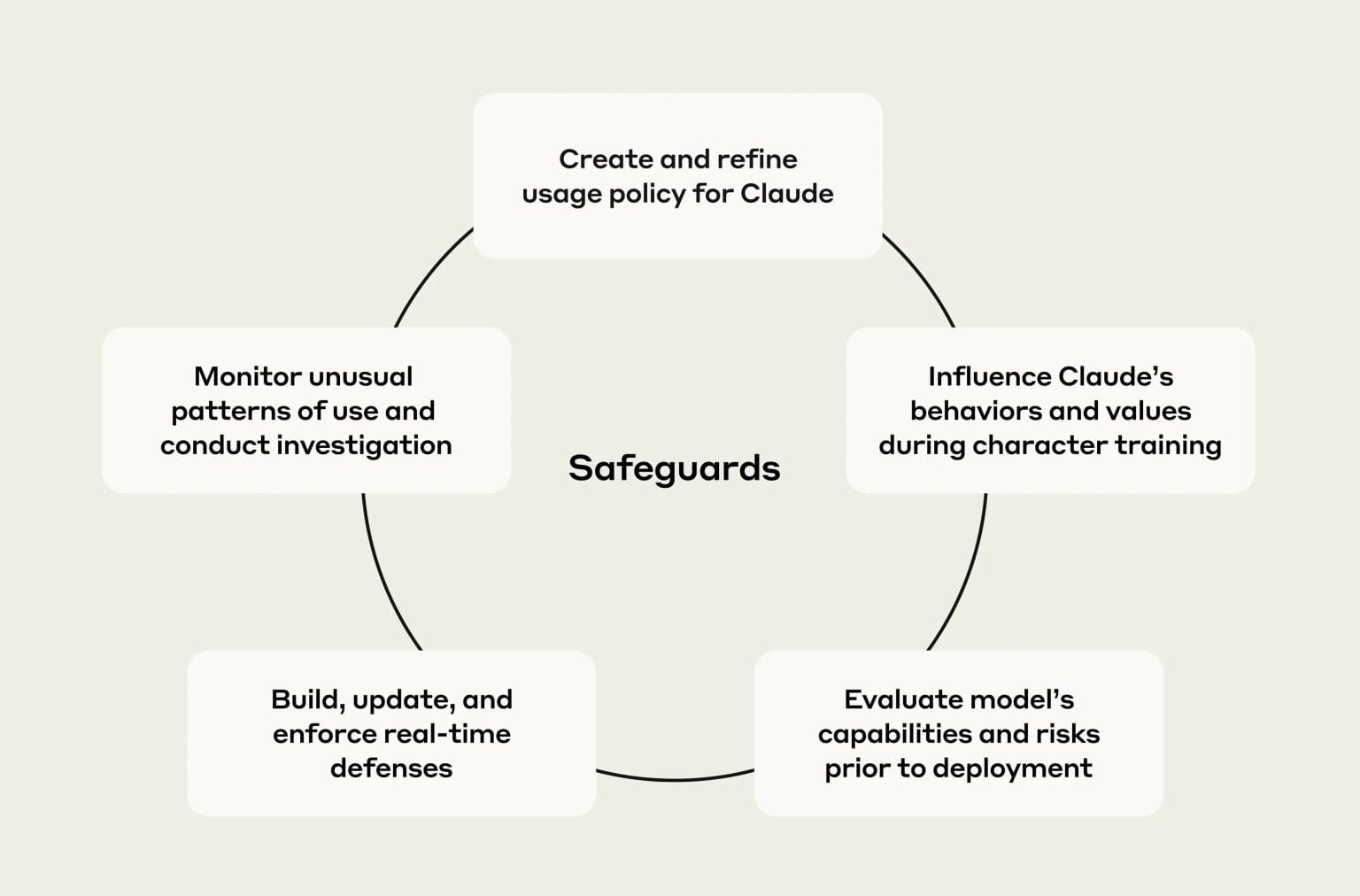
At the heart of the company’s approach is its Safeguards team, a cross-disciplinary group of policy experts, engineers, data scientists, and threat analysts. Rather than relying on a single barrier, Anthropic uses a “castle” model—layering defences from clear usage rules to real-time monitoring.
From Policy to Practice
It begins with a Usage Policy, a plain-language rulebook for what Claude can and cannot do. These guidelines cover everything from election integrity and child safety to responsible use in finance and healthcare.
To shape these rules, Anthropic applies its Unified Harm Framework—a structured method for weighing potential physical, psychological, economic, and societal risks. External experts, including specialists in terrorism and child protection, then conduct Policy Vulnerability Tests by attempting to push Claude into unsafe territory.
This process proved its worth during the 2024 US elections. Working with the Institute for Strategic Dialogue, Anthropic spotted a gap: Claude could return outdated voting information. The fix was simple but effective—a banner directing users to TurboVote, a non-partisan source for current election details.
Building Safety Into the Model
Anthropic doesn’t just bolt safety features on at the end—it bakes them into Claude from the start. Collaborations with groups like ThroughLine, a crisis support organization, have helped teach the model to respond sensitively to mental health conversations rather than refusing them outright. At the same time, Claude is trained to decline harmful requests, such as creating malicious code or assisting in scams.

Before any new version launches, Claude undergoes three major checks:
- Safety evaluations – Testing whether rules hold up in long, complex interactions.
- Risk assessments – Deep dives into high-stakes areas like cyber or biological threats, often with government or industry partners.
- Bias evaluations – Ensuring answers are fair, accurate, and free from skew based on politics, gender, race, or other factors.
Always-On Monitoring
After release, Anthropic uses a mix of automated systems and human reviewers to watch for problems. Specialised AI “classifiers” scan conversations in real time, flagging or redirecting harmful requests. Persistent misuse can lead to warnings or account suspension.
Beyond individual cases, the Safeguards team monitors patterns—looking for coordinated campaigns or emerging threats—while protecting user privacy. They even keep an eye on online spaces where bad actors might be developing new tactics.
A Shared Responsibility
Anthropic stresses that AI safety isn’t a closed project. The company actively works with researchers, policymakers, and the public to refine safeguards and adapt to new risks.
Anthropic’s approach shows that keeping AI safe is less about a single fix and more about constant, layered defence—starting with thoughtful rules, embedding values during training, testing relentlessly, and staying alert to new threats long after launch.



