

As artificial intelligence systems evolve from simple chatbots into autonomous, task-driven agents, the infrastructure behind them is being pushed to its limits. Agentic AI, designed to manage complex workflows and retain context over long periods, places entirely new demands on memory and storage, exposing a growing gap between what current hardware can process and what it can efficiently remember.
Foundation models are expanding rapidly, with parameter counts climbing toward the trillion mark and context windows stretching into the millions of tokens. While raw computing power continues to improve, the cost of maintaining long-term context is rising even faster. For organisations deploying agentic AI, this imbalance has become a major bottleneck.
At the centre of the issue is the Key-Value (KV) cache, the mechanism transformer-based models use to store conversational and operational history. This cache allows models to avoid recomputing past interactions, making real-time reasoning possible. In agentic systems, however, KV cache effectively becomes a form of persistent memory, growing steadily as agents interact across tools, sessions, and tasks.
Existing infrastructure offers an uncomfortable choice. Context can be stored in high-bandwidth GPU memory, which is fast but expensive and limited in capacity, or pushed to general-purpose storage, which is cheaper but introduces latency that undermines real-time performance. As context spills across these tiers, efficiency drops sharply, leaving powerful GPUs waiting idly for data and driving up energy use and overall costs.
To address this challenge, NVIDIA has introduced the Inference Context Memory Storage (ICMS) platform as part of its Rubin architecture. The idea is to create a new, purpose-built memory tier designed specifically for the high-speed, short-lived data that agentic AI relies on. NVIDIA CEO Jensen Huang described this shift as a natural step in AI’s evolution, noting that modern AI systems must reason over long horizons, use tools effectively, and retain both short- and long-term memory.

Unlike traditional enterprise data, KV cache does not need heavy durability guarantees or complex metadata management. It is derived data, critical for immediate performance but not intended for long-term retention. General-purpose storage systems, typically managed by CPUs, waste energy and time on features that agentic workloads simply do not need.
The ICMS platform introduces what NVIDIA refers to as a “G3.5” tier: an Ethernet-connected flash layer that sits between system memory and shared storage. Integrated directly into the compute pod and managed by NVIDIA’s BlueField-4 data processor, this layer offloads context management from host CPUs and provides petabytes of shared capacity without consuming scarce GPU memory.
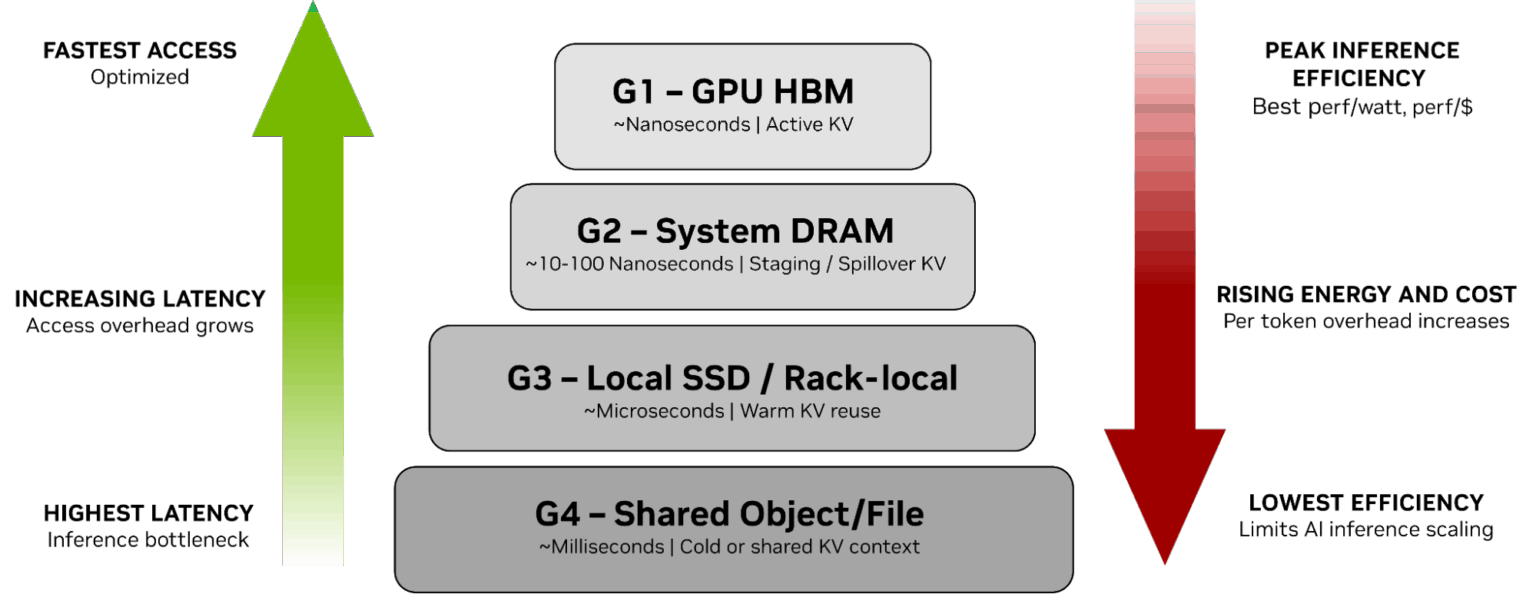
The performance gains are significant. By keeping active context closer to the GPU and prestaging it before it is needed, the system can reduce GPU idle time and deliver up to five times higher token throughput for long-context workloads. At the same time, the streamlined design cuts power consumption by avoiding the overhead of traditional storage protocols, improving energy efficiency by a similar margin.
Making this approach work requires tighter integration across the data plane. High-bandwidth, low-latency connectivity is delivered through NVIDIA’s Spectrum-X Ethernet, allowing flash storage to behave almost like local memory. Orchestration tools such as NVIDIA Dynamo and the Inference Transfer Library coordinate the movement of context between memory tiers, while the DOCA framework treats KV cache as a first-class resource rather than an afterthought.
The ecosystem is already forming around this architecture. Major storage and infrastructure vendors, including Dell Technologies, HPE, IBM, Pure Storage, and others, are building systems based on BlueField-4, with availability expected later this year.
For enterprises, adopting a dedicated context memory tier has broader implications. CIOs will need to rethink data classification, treating AI context as ephemeral but latency-sensitive, distinct from durable compliance data. Data centre planning will also need to account for higher compute density, along with the cooling and power requirements that come with it.
Ultimately, scaling agentic AI is no longer just about choosing the fastest GPU. It requires rethinking the entire memory hierarchy to ensure that growing model intelligence does not come at an unsustainable cost. By introducing a specialised layer for AI context, organisations can unlock higher performance, better energy efficiency, and a more practical path to deploying intelligent agents at scale.



